Library Innards
What exactly happens under the hood
This post aims to delve deeper into how the library works. Topics closely related to EGL, GLES and GPU vs CPU computing will be elaborated on here.
First of all, the library’s aim is to utilize BBB’s GPU block for computations. In OpenGL ES 3.0 we have compute shaders which can be used to perform computations utilizing GPUs. Also OpenCL is used for heterogeneous computations on general platforms, such as PC or embedded devices running Linux operating System. Since BBB’s GPU chips (SGX530) don’t support OpenGL ES 3.0 but support it’s 2.0 version, we have to utilize vertex and fragment shaders for our computations.
This is the old-school way of doing GPGPU computing before compute shaders were introduced. The data goes through vertex shader and then the actual computation happen in fragment shader. There of course remain some key decision and issues that have to be tackled, such as data format used for computations, size of the data to be computed and some GPU limitations (such as inability to sample textures in branches on SGX architectures).
This post will feature a lot of abbreviations which may be cryptic at first (or not if you are familiar with the Linux graphics stack). If you feel you are stuck and do not understand them, please refer to this post. (I of course did not find all of my answers there but at least had a stronger understanding thanks to it).
Context creation
When we usually render something we need a context which, citing Apple’s developer pages is:
a container for state information. When you designate a rendering context as the current rendering context, subsequent OpenGL commands modify that context’s state, objects attached to that context, or the drawable object associated with that context. The actual drawing surfaces are never owned by the rendering context but are created, as needed, when the rendering context is actually attached to a drawable object.
In our case we are using EGL to create and manage our context. More specifically we use a pixel buffer which is an off-screen rendering target, which means we do not render to any window and instead save our data in an arbitrary memory location.
The following code creates and uses the context for our library:
// g_helper contains following fields:
typedef struct
{
EProgramState state;
GLint ESShaderProgram;
EGLDisplay display;
EGLConfig config;
EGLContext context;
EGLSurface surface;
int height;
int width;
} GLHelper;
GLHelper g_helper;
g_helper.display = eglGetDisplay((EGLNativeDisplayType)0);
if (!g_helper.display)
ERR("Could not create display");
if (eglInitialize(g_helper.display, &major, &minor) == 0)
ERR("Could not initialize display");
printf("EGL API version %d.%d\n", major, minor);
// checking the extensions and choosing a config is skipped for brevity
if (eglBindAPI(EGL_OPENGL_ES_API) == 0)
ERR("Could not bind the API");
EGLint eglSurfaceAttibutes[] = {
EGL_WIDTH, width,
EGL_HEIGHT, height,
EGL_NONE
};
g_helper.surface = eglCreatePbufferSurface(g_helper.display, g_helper.config, eglSurfaceAttibutes);
if (g_helper.surface == EGL_NO_SURFACE)
ERR("Could not create EGL surface");
EGLint eglContextAttributes[] = {
EGL_CONTEXT_CLIENT_VERSION, 2,
EGL_NONE
};
g_helper.context = eglCreateContext(g_helper.display, g_helper.config, EGL_NO_CONTEXT, eglContextAttributes);
if (g_helper.context == EGL_NO_CONTEXT)
ERR("Could not create EGL context");
if (eglMakeCurrent(g_helper.display, g_helper.surface, g_helper.surface, g_helper.context) != EGL_TRUE) // EGL_NO_SURFACE??
ERR("Could not bind the surface to context");
EGLint version = 0;
eglQueryContext(g_helper.display, g_helper.context, EGL_CONTEXT_CLIENT_VERSION, &version);
printf("EGL Context version: %d\n", version);
With the context set up, we can create our textures and bind them to memory and the framebuffer object. But before we do this, one small caveat: extensions we will be using have to be checked and GLES configs have to be chosen with following helper functions:
int gpgpu_check_egl_extensions()
{
int ret = 0;
if (!g_helper.display)
ERR("No display created!");
const char* egl_extensions = eglQueryString(g_helper.display, EGL_EXTENSIONS);
if (!strstr(egl_extensions, "EGL_KHR_create_context"))
ERR("No EGL_KHR_create_context extension");
if (!strstr(egl_extensions, "EGL_KHR_surfaceless_context"))
ERR("No EGL_KHR_create_context extension");
bail:
return ret;
}
int gpgpu_find_matching_config(EGLConfig* config, uint32_t gbm_format)
{
int ret = 0;
if (!g_helper.display)
ERR("No display created!");
EGLint count;
#ifndef BEAGLE
static const EGLint config_attrs[] = {
EGL_BUFFER_SIZE, 32,
EGL_DEPTH_SIZE, EGL_DONT_CARE,
EGL_STENCIL_SIZE, EGL_DONT_CARE,
EGL_RENDERABLE_TYPE, EGL_OPENGL_ES2_BIT,
EGL_SURFACE_TYPE, EGL_WINDOW_BIT,
EGL_NONE
};
#else
static const EGLint config_attrs[] = {
EGL_RED_SIZE, 8,
EGL_GREEN_SIZE, 8,
EGL_BLUE_SIZE, 8,
EGL_ALPHA_SIZE, 8,
EGL_SURFACE_TYPE, EGL_PBUFFER_BIT,
EGL_RENDERABLE_TYPE, EGL_OPENGL_ES2_BIT,
EGL_NONE
};
#endif
if (!eglGetConfigs(g_helper.display, NULL, 0, &count))
ERR("Could not get number of configs");
EGLConfig* configs = malloc(count * sizeof(EGLConfig));
if (!eglChooseConfig(g_helper.display, config_attrs, configs, count, &count) || count < 1)
ERR("Could not choose configs or config size < 1");
printf("Seeked ID %d\n", gbm_format);
for (int i = 0; i < count; ++i)
{
EGLint format;
#ifndef BEAGLE
if (!eglGetConfigAttrib(g_helper.display, configs[i], EGL_NATIVE_VISUAL_ID, &format))
ERR("Could not iterate through configs");
#else
if (!eglGetConfigAttrib(g_helper.display, configs[i], EGL_CONFIG_ID, &format)) // TODO: should be matched in a more robust way
ERR("Could not iterate through configs");
#endif
printf("EGL format: %d Seeked: %d\n", format, gbm_format);
dumpEGLconfig(configs[i], g_helper.display);
if (gbm_format == format)
{
*config = configs[i];
free(configs);
return ret;
}
}
ERR("Failed to find a matching config");
bail:
if (configs)
free(configs);
return ret;
}
The config chooser wrapper needs different parameters depending whether we are using our host or the BBB. Special parameters such as bit depth and surface type have to be queried from the system and chosen.
Framebuffer Object creation
With our context set up and running, we can now create the actual objects to which we will be rendering in terms of OpenGL ES. These objects as you already know are called framebuffer objects or in short FBOs. As mentioned earlier EGL will be used to translate our OpenGL ES calls to actual platform-specific calls.
In our case, we are first creating a texture we will be rendering to(glTexImage2D()) and then we bind it to our current framebuffer as color attachment number 0 with glFramebufferTexture2D(). Finally, we check if the framebuffer was created properly, otherwise we could receive complete garbage on our rendering calls. One thing that eluded me for a long time was missing glViewport() call which sets the actual size of the rendering buffer and does the screen-to-buffer translations. without setting it properly you would be getting output from only a tiny fragment of the texture instead of your input width and height, rendering (no pun intended) this library useless.
The code is simple to follow and looks like this:
int gpgpu_make_FBO()
{
int ret = 0;
GLuint texId, fbId;
glGenTextures(1, &texId);
glBindTexture(GL_TEXTURE_2D, texId);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, g_helper.width, g_helper.height, 0, GL_RGBA, GL_UNSIGNED_BYTE, 0); // allows for floating-point buffer in ES2.0 (format should be RGBA32F)
glBindTexture(GL_TEXTURE_2D, 0);
glGenFramebuffers(1, &fbId);
glBindFramebuffer(GL_FRAMEBUFFER, fbId);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texId, 0);
// magic trick!
glViewport(0, 0, g_helper.width, g_helper.height);
ret = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if (ret != GL_FRAMEBUFFER_COMPLETE)
gpgpu_report_framebuffer_status(ret);
else
ret = 0;
// save the FBO texture as the primary output for chaining
g_chainHelper.output_texId0 = texId;
g_chainHelper.fbId = fbId;
return ret;
}
If you are eager for more knowledge, here it comes. You can learn about how to render to a texture and implement MSAA.
Data transfers
This is probably the crux of our library and was the most time-consuming part of the entire project: inputting the data properly and getting it back from the texture. Astute readers probably noticed that we are using GL_UNSIGNED_BYTEs as the format of our FBO. Because we are using unsigned bytes we probably need to do some translations our input data => GPU data format => our output data, which in the first case are simply a regular C-style cast.
What happens later depends on the input data and how precisely we want to represent the data in GPU. For the most common type of conversion which is a quartet of unsigned bytes to IEEE754 float it is shown in a previous blog post.
The various conversions and how the data is transformed are shown below:
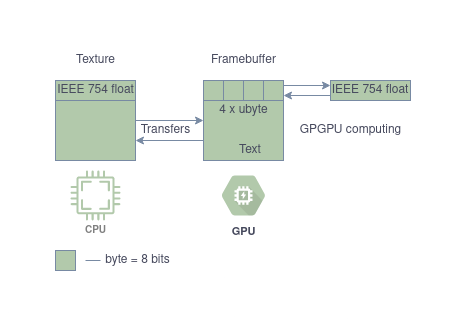
The code behind is generally simple and looks very similar in every case of single-shot operations
int GPGPU_API gpgpu_arrayAddition(float* a1, float* a2, float* res)
{
int ret = 0;
if (g_helper.state != READY)
ERR("Call gpgpu_init() first!");
unsigned char* buffer = malloc(4 * g_helper.width * g_helper.height);
GLuint texId0, texId1;
gpgpu_make_texture(a1, g_helper.width, g_helper.height, &texId0);
gpgpu_make_texture(a2, g_helper.width, g_helper.height, &texId1);
// inputs are float textures, output is a vec4 of unsigned bytes representing the float result of one texel
// we need to extract the bits following the IEEE754 floating point format because GLES 2.0 does not have bit extraction
gpgpu_build_program(REGULAR, ARRAY_ADD_FLOAT);
// create the geometry to draw the texture on
GLuint geometry;
glGenBuffers(1, &geometry);
glBindBuffer(GL_ARRAY_BUFFER, geometry);
glBufferData(GL_ARRAY_BUFFER, 20*sizeof(float), gpgpu_geometry, GL_STATIC_DRAW);
// setup the vertex position as the attribute of vertex shader
gpgpu_add_attribute("position", 3, 20, 0);
gpgpu_add_attribute("texCoord", 2, 20, 3);
// do the actual computation
// bind textures to their respective texturing units
// add texture uniforms to fragment shader
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texId0);
gpgpu_add_uniform("texture0", 0, "uniform1i");
glActiveTexture(GL_TEXTURE0 + 1);
glBindTexture(GL_TEXTURE_2D, texId1);
gpgpu_add_uniform("texture1", 1, "uniform1i");
glActiveTexture(GL_TEXTURE0);
if (gpgpu_report_glError(glGetError()) != 0)
ERR("Could not prepare textures");
// finally draw it
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
//////////
// magic happens and the data is now ready
// poof!
//////////
glReadPixels(0, 0, g_helper.width, g_helper.height, GL_RGBA, GL_UNSIGNED_BYTE, buffer);
// convert from unsigned bytes back to the original format
// copy the bytes as floats
for (int i = 0; i < 4 * g_helper.width * g_helper.height; i += 4)
{
res[i / 4] = *((float*)buffer + i / 4);
}
bail:
if (buffer)
free(buffer);
return ret;
}
We need to create textures to which we load our input data and we allocate the output buffer. We create our shader program and set up uniforms and attributes (generally only uniforms change). The actual rendering (computation) happens in glDrawArrays() call and the data is ready to be copied out afterwards.
After the computation is complete, the data is read out with glReadPixels() which reads it out to the temporary buffer wrom which it is copied and cast to the proper type.
(I tried removing this copy and instead cast the contents of the buffer to the resultant type, but it worked fine only on my host and resulted in a SIGBUS on BBB, thus I believe the copy is unfortunately necessary).
Single-shot vs chain API
Coming so far, I need to mention that the library features additonal computing mode as well - the chain API, which allows for executing virtually infinite operations on the data in our GPU before moving the data back to CPU. The motivation behind introducing such API is that usually the overhead which comes from moving the data to and fro the GPU.
The difference between these two APIs is shown in the picture below:
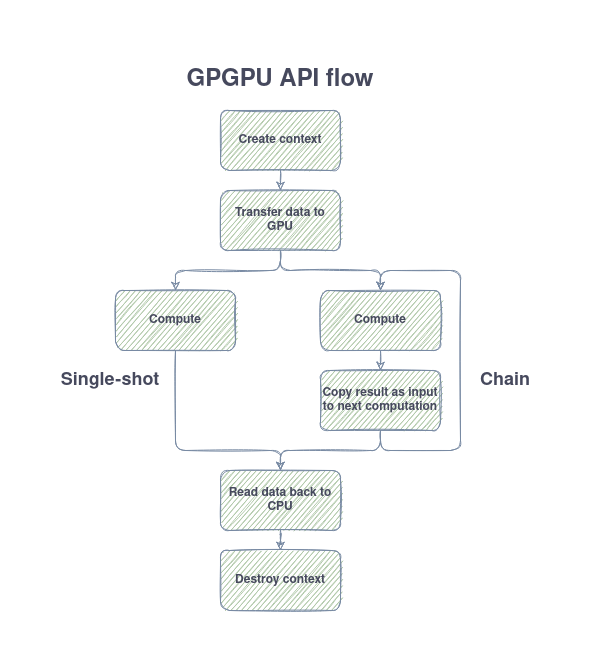
The crucial difference is in the usage of two FBO textures and swapping between them after each call + copying data from the output of last FBO to the input texture of next operation. After all operations are performed, the data is finally read out and converted as in the usual case.
The API has to be called in a particular way, which is shown below:
// construct the computation chain
EOperation ops[] = { ADD_SCALAR_FLOAT, ADD_SCALAR_FLOAT };
UOperationPayloadFloat* payload = malloc(2 * sizeof(UOperationPayloadFloat));
payload[0].s = 2.0;
payload[1].s = 2.0;
if (gpgpu_chain_apply_float(ops, payload, 2, a1, res) != 0)
printf("Could not do the chain computation\n");
Where payload type is an union:
typedef union
{
float s;
float* arr;
int n; // kernel size
} UOperationPayloadFloat;
Some operations, like 2D convolution require two slots in the payload, and this is boldly stated in the documentation.
The differences and benchmarks from running both APIs and different operations are available in this blog post.
Conclusion
Hopefully this post achieved what it was meant to do - explain more precisely what and how happens under the hood of this library. Equipped with this knowledge you can probably help expand this library or even develop your GPGPU solutions if you don’t plan to use OpenGL as the backend for computations.