Week 5
Coding
Finally computing
This week was a breakthrough as the library finally computes something using GPU. A lot of time went into figuring how to do it (last week’s flashbacks) and a lot digging around obscure internet sites to understand what I was missing.
First of all I tried computing very small textures (2x2) and seeing if I am getting correct outputs from the shader, but without an insight into the textures themselves it was very time consuming. Hence, I found a program called apitrace which shows all EGL/OpenGL calls made during rendering of every frame (in my case just one). I was then able to see that I had weird texture mapping coming out of my vertex shader, which proved to be caused by GL Vertex/Texture coordinates mismatch as visible in the picture below:
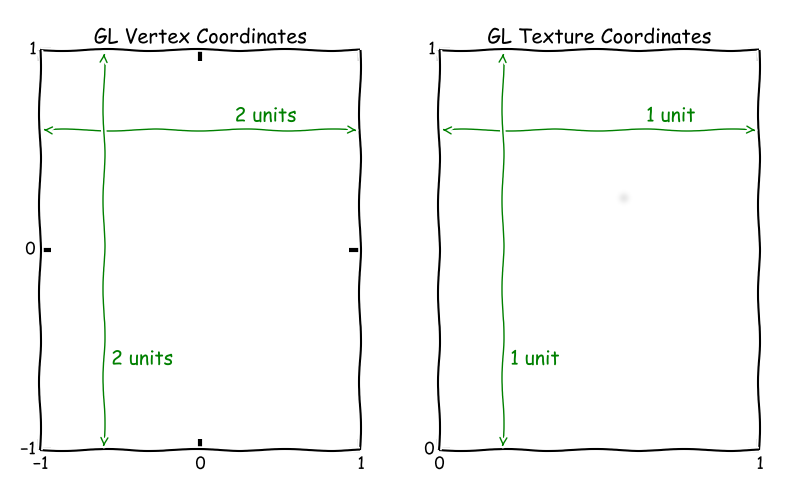
The missing component which caused my data to be mapped wrongly was glViewport() - a function call which sets up the viewport rectangle and in turn allows the texture to be sampled properly.
This was the AHA moment for me!
Also, in order to have correct values I had to rescale the values coming from my textures by 255.0 and divide it by 255.0 at the end. It is because the values are assumed to be in 0.0-1.0 range when packed into the texture. I used the IEEE754 float packing and unpacking from unsigned char’s stored in the textures following the guide from this website. The code there has a mistake which needs correction and the good code is shown below:
#ifdef GL_FRAGMENT_PRECISION_HIGH
precision highp float;
#else
precision mediump float;
#endif
uniform sampler2D texture0;
uniform sampler2D texture1;
varying vec2 vTexCoord;
vec4 pack(float value)
{
if (value == 0.0) return vec4(0);
float exponent;
float mantissa;
vec4 result;
float sgn;
sgn = step(0.0, -value);
value = abs(value);
exponent = floor(log2(value));
mantissa = value * pow(2.0, -exponent) - 1.0;
exponent = exponent + 127.0;
result = vec4(0);
result.a = floor(exponent / 2.0);
exponent = exponent - result.a * 2.0;
result.a = result.a + 128.0 * sgn;
result.b = floor(mantissa * 128.0);
mantissa = mantissa - result.b / 128.0;
result.b = result.b + exponent * 128.0;
result.g = floor(mantissa * 32768.0);
mantissa = mantissa - result.g / 32768.0;
result.r = floor(mantissa * 8388608.0);
return result / 255.0;
}
float unpack(vec4 texel)
{
float exponent;
float mantissa;
float value;
float sgn;
sgn = -step(128.0, texel.a);
texel.a += 128.0 * sgn;
exponent = step(128.0, texel.b);
texel.b -= exponent * 128.0;
exponent += 2.0 * texel.a - 127.0;
mantissa = texel.b * 65536.0 + texel.g * 256.0 + texel.r;
value = pow(-1.0, sgn) * exp2(exponent) * (1.0 + mantissa * exp2(-23.0));
return value;
}
void main(void)
{
vec4 texel1 = texture2D(texture0, vTexCoord);
vec4 texel2 = texture2D(texture1, vTexCoord);
float a1 = unpack(texel1 * 255.0); // need to rescale it before?
float a2 = unpack(texel2 * 255.0);
gl_FragColor = pack(a1 + a2);
}
Specifically, the value calculation was wrong, it lacked setting the proper sign. You may see the article for original code and compare the differences.
Since debugging shaders is almost impossible (yes it shocked me as well…), I had to test the actual code in the CPU, so I developed a C program mimicking the GPU code.
Adding 2D Convolution
The next operation added, was 2D convolution using a 3x3 kernel. In order to do it, the 3x3 texture has to be sampled and stored for the computation of one texel (texture pixel - one floating-point value). Of course boundaries have to be replaced with zeros. This introduces a slight overhead but hopefully is much faster than in the CPU.
The code below shows how I do it:
#ifdef GL_FRAGMENT_PRECISION_HIGH
precision highp float;
#else
precision mediump float;
#endif
uniform sampler2D texture0;
uniform sampler2D texture1;
uniform float w; // inverse dimension of the texture - necessary to not overflow floats
varying vec2 vTexCoord;
// same as above
vec4 pack(float value);
float unpack(vec4 texel);
void main(void)
{
const int kSpan = 3;
const int spread = kSpan / 2;
vec4 samp[kSpan * kSpan];
vec4 value;
// load the part of the image which will be used for convolution from texture memory
for (int i = -spread; i <= spread; ++i)
{
for (int j = -spread; j <= spread; ++j)
{
if ((vTexCoord.x + float(j) * w) > 1.0 ||
(vTexCoord.x + float(j) * w) < 0.0 ||
(vTexCoord.y + float(i) * w) > 1.0 ||
(vTexCoord.y + float(i) * w) < 0.0)
{
value = vec4(0.0);
}
else
{
value = texture2D(texture0, vTexCoord + vec2(float(j) * w, float(i) * w));
}
samp[(i + spread) * kSpan + (j + spread)] = value;
}
}
float result = 0.0;
float step = 1.0 / float (1 + kSpan); // how much step through the kernel texture
// do the convolution (dot product)
for (int i = 0; i < kSpan; ++i)
{
for (int j = 0; j < kSpan; ++j)
{
result += unpack(samp[i * kSpan + j] * 255.0) * unpack(texture2D(texture1, vec2(step * float(j + 1), step * float(i + 1))) * 255.0);
}
}
// do the last transformation to float
gl_FragColor = pack(result);
}
As before, we have to rescale the texels we sample in order to fulfil the requirements of conversion. In order to understand how 2D convolution works I have some sources you may peruse:
- https://songho.ca/dsp/convolution/convolution2d_example.html
- https://engineering.purdue.edu/~bouman/ece637/notes/pdf/Filters.pdf
- https://www.allaboutcircuits.com/technical-articles/two-dimensional-convolution-in-image-processing/
I plan to add 1D convolution and maybe convolution with striding.
Restructurizing the files
I decided to split the files into headers and sources and especially hide all the implementation details into gpgpu_int.h. I also moved shader loading from a file instead of the raw code. This allows for easier extending the library further and reduces the mental overhead required to understand the library code.
Testing
This week I will also develop some CPU/GPU benchmarks which will be callable from the CLI with various array sizes.
Headless on BBB
Headless rendering on BBB is progressing slowly - I opened a query on Imagination’s forum and it is investigated. Meanwhile I ordered a headless ghost plug which will emulate any display I fathom. This way I can test my code on hardware and not be stalled by internal issues in the PVR stack. Hopefully it won’t be required to use once the library is ready and shiny!
I tried running the code on BBB with the headless plug but it seems to be having some issues still. Notably, the default format for GPU data on BBB is RGB565 (which means 5 bits for Red, 6 for Green and 5 for Blue) and my requirements are for ARGB8888 in order to map the 32-bit float evenly to all 4 bytes.
I was able to run the code to some extent (right until creating the Window), without usage of GBM and with simple EGL calls. However, at this point I got stuck and spent a lot of time trying to debug what the problem is.
It is worth mentioning that this is probably some issue with the internal format, as even PVR examples do not run with this configuration. I opened a query at Imagination’s forum to ask for help on this.