Benchmarking
This post/page is a collection of benchmarks made both on the Beaglebone Black rev. C and my PC with NVIDIA GTX960M GPU. The operations are performed with 32-bit buffer on both devices.
Array addition floating-point
Without optimizations
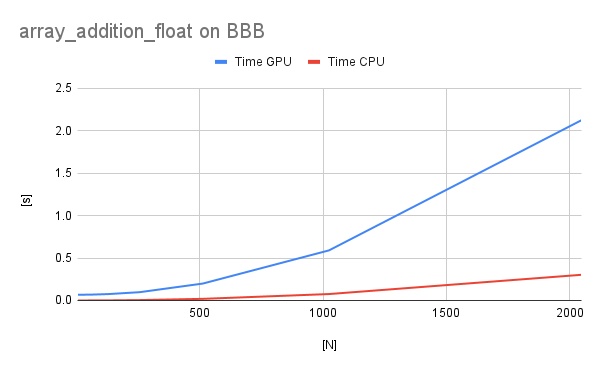
It can be seen that in case of BBB the GPU is always slower than CPU and this is exacerbated with the increasing size of the data transferred to and fro the GPU. The overhead of data transfers is very big, so in future tests I will see how expensive the operations on the GPU have to be to make up for the overhead.
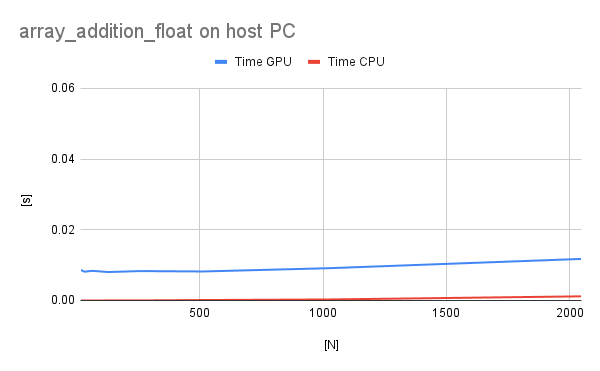
On the PC the differences are much smaller, which shows that the bus transfers between CPU and GPU are much faster. Also the execution time is much faster, because the CPU and GPU are much stronger.
-O3 enabled
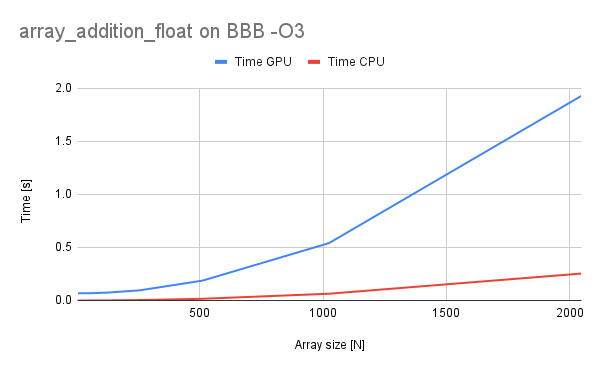
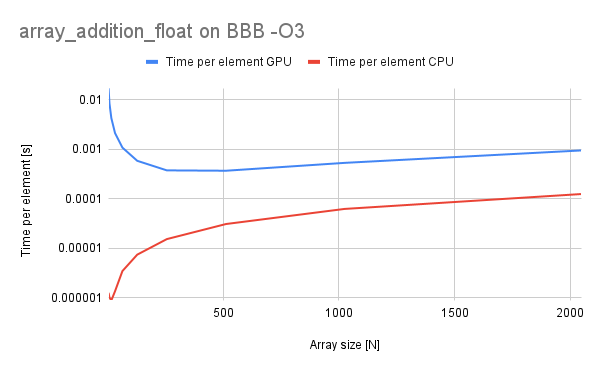
It can be seen that enabling optimizations made the code execute faster in both cases. Also the time per-element is a good metric because it shows whether the processor is executing optimally or sub-optimally and in our case we can see that the relationship is almost linear in both cases.
Time per-element is shown in logarithmic vertical scale and is increasing exponentially in both cases.
Array addition fixed-point 16-bit
Without optimizations
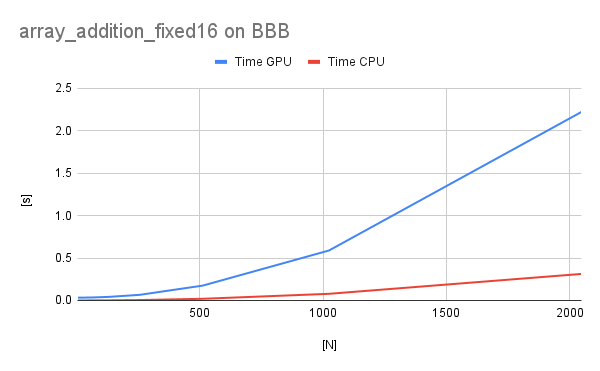
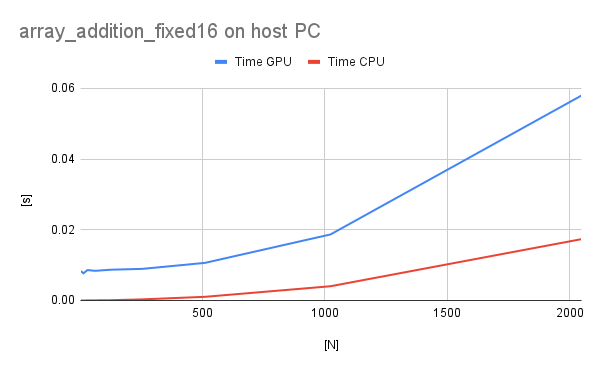
In case of fixed-point operations, the results are very similar to floating-point for the BBB. However, for the host PC GPU execution is significantly slower (probably due to fixed-to-float transformations).
-O3 enabled
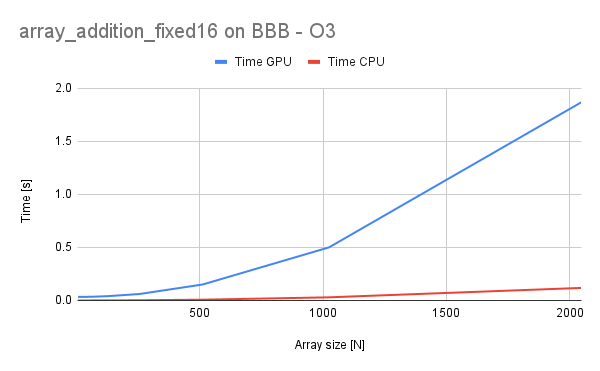
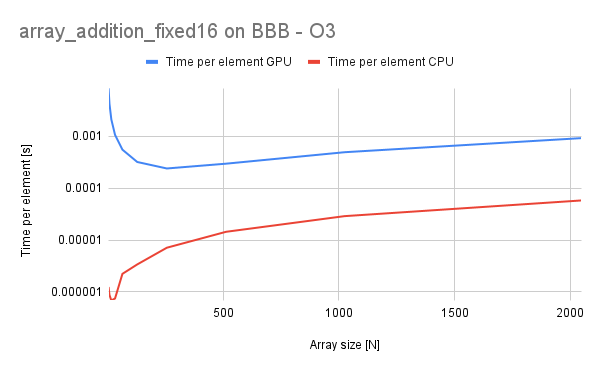
For the fixed-point operations, we can see that a significant speedup is achieved on the CPU side, with a slighly lesser speedup on the GPU. Also time-per-element for the GPU is rising which shows that it is less resilient to scalabilty than in the floating-point case.
2D convolution floating-point
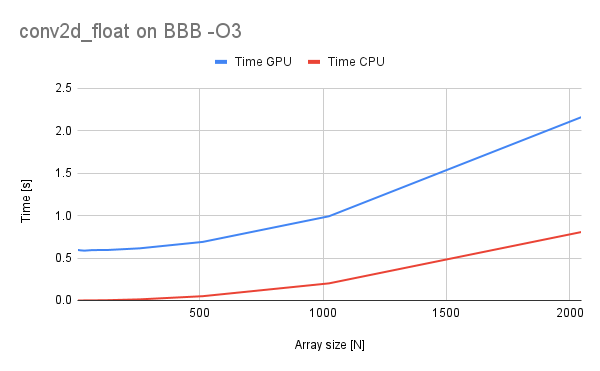
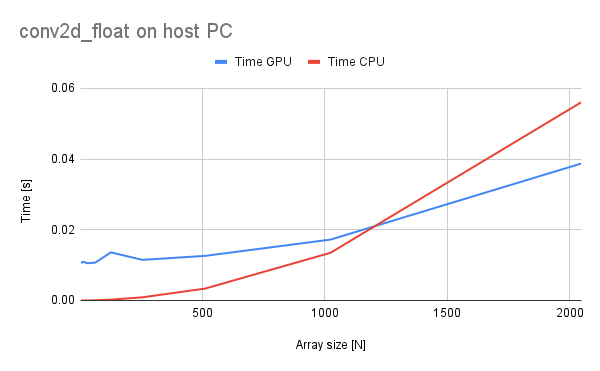
The -O3 optimizations are enabled in this benchmark case.
Finally, we can see some operations in which GPU is faster than the CPU (covers up for the data transfer overhead). On my host PC passing the magic mark of 1024 elements causes the GPU to be faster! Unfortunately on the BBB it is not the case and faster operations are required still. The benchmark here is a 3x3 convolution kernel of floats.
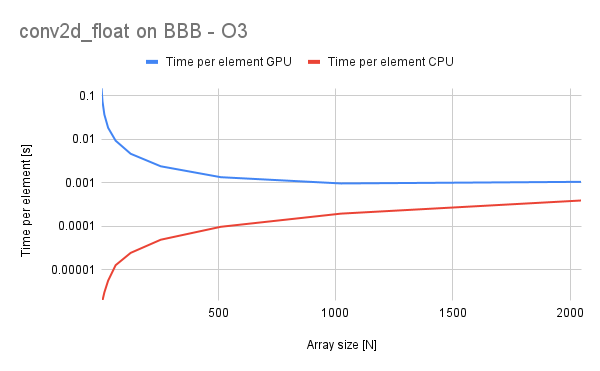
Interestingly, in this case the time per-element for GPU is asymptotic to the one for CPU and can probably surpass it if we could have infinite textures available on our BBB. However, we are limited to 2048x2048 texture sizes.
Noop operations floating-point
Small introduction - this benchmark is supposed to be a baseline to show how expensive are CPU<=>GPU data transfers on BBB and host PC. This knowledge is valuable when assessing when to use this library and what sizes of the data/complexity of operations to use.
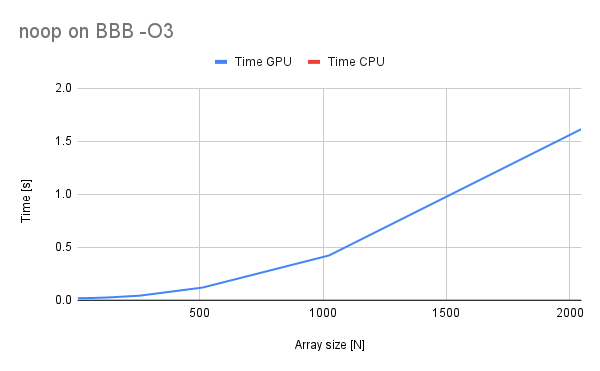
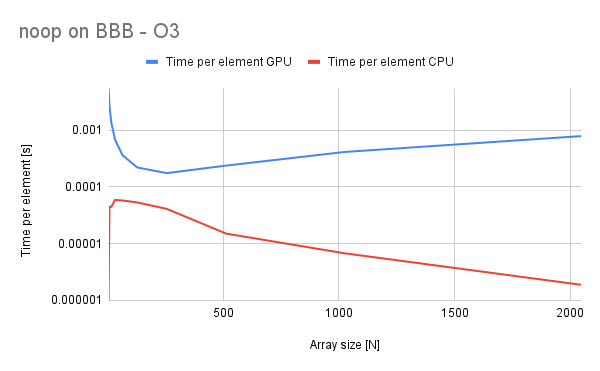
As we can see, the noops are a cinch to our CPU as the compiler is clever enough to do them all in just a single assembly instruction (probably our friend mov or its relative). The situation is much worse in case of GPU, because we have to copy the data over and copy it back to the CPU once we are done with out noop. The problem worsenes with the data size however not very much. The time-per-element metric shows us that this time is fairly linear.
On the PC the problem is quite similar and the CPU noops take literally no time, so I did not include that graph here.
Equipped with this knowledge, we can now deduct the time it takes for the data to travel to the GPU to assess when we should increase our computation complexity to cover up for the data transfer time.
Chain API testing with 2D convolution 5x5 kernels - 2 repetitions
With the chain API implemented, we can now utilize the BBB to its limit (it seems like quite literally). 2D Convolution with 5x5 kernel done twice on the data of different sizes was performed to assess the fitness of our board in this benchmark.
.png)
-element.png)
We can now clearly see that there are sizes and operations which are faster on SGX GPU than on the CPU onboard the BBB! This is great news as we can now utilize the board as a heterogeneuous computing device and put it to some more intensive use!
Most importantly, we can see that with the increase in data size, we get a reduction of time-per-element, which is our crucial marker telling us how well the BBB performs.
.png)
On the host, situation is obviously much better - the CPU time grows rapidly and GPU reacts much more slowly to data size increase. Sometimes I wish I had the same GPU on my BBB as I have on my laptop :) - the electricity bills would increase quite heavily though!
As I did more tests with greater number of repetitions I found out that a fixed overhead of data transfers(copying from old result texture to new input one) is added a number of times we do the chained computation. This is worth remembering when using the library.
For anyone interested in the actual data that backs up these graphs - here it is.